
递归和堆栈
递归
递归,简单来说就是函数在 return 的时候调用了函数自身。比如这个例子:
1 | function pow(x, n) { |
功效与 Math.pow() 相同。
比如计算 pow(2, 4) ,递归经过下面几个步骤:
- pow(2, 4) = 2 * pow(2, 3)
- pow(2, 3) = 2 * pow(2, 2)
- pow(2, 2) = 2 * pow(2, 1)
- pow(2, 1) = 2
最大的嵌套调用次数(包括首次)被称为 递归深度。在上面的那个例子中,正好是 n。
在 JavaScript 引擎中,最大递归深度会被受限。引擎在最大迭代深度是 10000 及以下时是可靠的,有些引擎可能允许更大的最大深度,但是对于大多数引擎来说, 100000 可能就超出限制了。所以,有一种尾递归的调用方式诞生了,但是目前还没有被完全支持,只能用于简单场景。
那什么是尾递归呢?
尾递归
尾递归中也包含递归这个词语,所以还是离不开递归。那么尾递归与普通递归有什么不同呢?
尾递归函数在 return 的时候除了常量,只会 return 自身函数,而不会 return 涉及到自身函数与其他函数或者常量的计算。
同样是上面的例子,如果 pow 函数 return 的只是 pow(x, n - 1) 而不包含 x * ,那么这就是一个尾递归函数。
那么与普通递归有什么不同呢?
普通递归函数因为涉及到了计算,所以会等最后一个深度的函数执行完成在回过来执行上一个函数,然后依次释放执行过的函数的内存空间,所以会存在最大深度的问题。
但是如果是尾递归,因为每只都是调用函数本事,不存在计算,所以,之前的函数不会占用内存空间,因而没有最大递归深度的概念。
1 | // 递归 |
如果 n 的值足够大,你会发现还是会报出栈溢出错误,并没有进行尾调用优化。因为上面说了,目前浏览器还没有完全支持这个方法。不过虽然没有支持,但是这种方法的调用也比普通递归好上一点。因为尾递归把时间复杂度从 $o(n)$ 降低到了 $o(1)$。
如果想要了解哪些语言支持尾递归,可以自行上 Google Search。
执行上下文和堆栈
递归函数在调用的时候为什么会存在 栈溢出 的情况?就是因为递归函数在执行的时候都是先执行的都是没有被计算的,仅仅只是保留在执行上面文中,等待后面的计算完成在返回来计算之前的。例如上面的例子
1 | function pow1(x, n) { |
在执行的时候,这样堆栈:
Context: {x: 2, n: 4, at: line 1} 调用
pow(2, 4)Context: {x: 2, n: 3, at: line 2} 调用
pow(2, 3)Context: {x: 2, n: 2, at: line 2} 调用
pow(2, 2)Context: {x: 2, n: 1, at: line 2} 调用
pow(2, 1)接着是
n === 1的时候,找到了出口return x。开始出栈
new Function ???
这种语法很少用到,估计在有限的程序员生涯也不会用到这种语法吧。但是很有趣,所以这里写写。
创建函数的语法:
1 | let func = new Function ([arg1, arg2, ...argN], functionBody); |
最后一个函数是函数体,如果只有一个参数,那他就是函数体。
1 | let sum = new Function('a', 'b', 'return a + b'); |
只有一个参数(即函数体):
1 | let sayHi = new Function('alert("Hello")'); |
还以一个问题,使用这种当时创建的函数,只能访问全局变量
1 | function getFunc() { |
调度:setTimeout 与 setInterval
这两个函数都不陌生,平时也都用的挺多的。尤其是在 requestAnimationFrame 不是特别友好的时候,常常用来写动画效果。
按照我之前的写法
1 | function say() { |
上面的代码在一秒中以后执行,没有丝毫问题。上面的函数是没有参数的情况,其实还有很多的时候所需要执行的函数是带有参数的。如果带有参数,我一般是这样做的:
1 | function sayHi(phrase, who) { |
其实还有另一种写法,来看看 setTimeout 的语法吧:
1 | let timerId = setTimeout(func|code, [delay], [arg1], [arg2], ...) |
第一个参数可以是一段代码,但是不建议这样做了。第二哥参数是延时时间。以前我就以为只有两个参数。从上面的语法中可以看出,其实还有很多参数的。这些参数就是所需执行的函数需要的参数,所以上面的代码还可以这样:
1 | function sayHi(phrase, who) { |
这样看起来就好看多了。
第二点就是这两个函数的返回值,返回值是一个 timerID ,是一个 number 类型的值。
接下来就是对比以下两者的使用,用 setTimerout 模仿一个 setInterval
1 | function func(s) { |
同样都是一秒的延迟,但是每一次都是 setInterval 先打印出来。如果将 line1 与 line2 调换顺序,除了第一次是 setInterval 后执行,后面都是先执行了。为什么呢?因为 func 的执行所花费的时间“消耗”了一部分间隔时间。用图来解释:
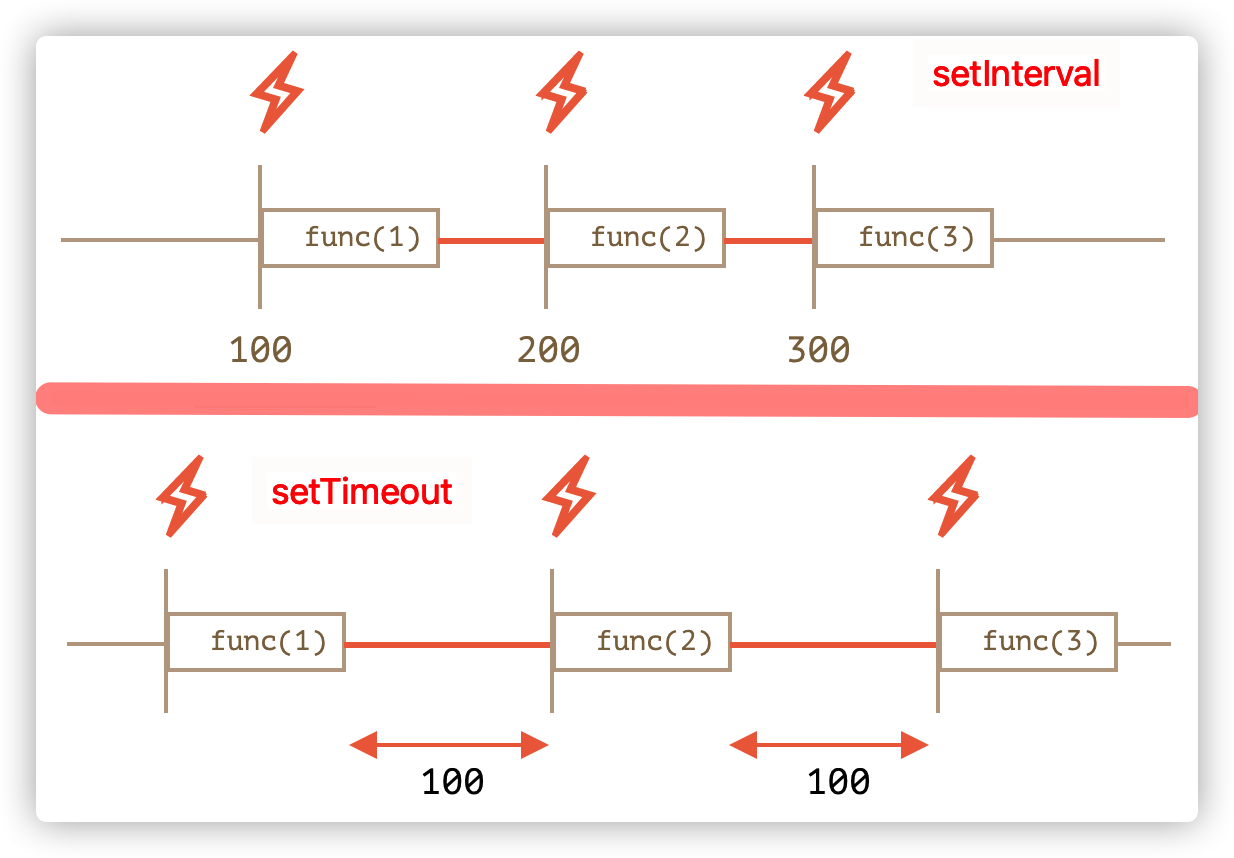
诶。这就很明显了嘛。

